数据血缘关系在企业的数据治理中是非常重要的一个环节,关于数据血缘在企业数据治理中的重要作用,可以参考这篇文章。SQL 语言在数据处理中被广泛使用,SQL 语句中包含了丰富的数据血缘关系,关于什么是 SQL 中的数据血缘,如何发现这些隐藏在 SQL 语句中数据血缘,请参考这篇文章。
本文主要介绍如何利用 Gudu SQLFlow 数据血缘分析工具提供的 UI,Rest API 及 Java 库来快速获取复杂 SQL 语句中的数据血缘,并根据需要,集成在自己的数据治理平台中。
一个稍微有点复杂的 SQL 语句
我们利用下面这个稍微有点复杂的 SQL 语句来演示如何利用 Gudu SQLFlow 快速获取各种数据血缘关系,如果你有更复杂的 SQL 语句或者存储过程 (stored procedure) 需要处理,那么更需要一个像 Gudu SQLFlow 这样的数据血缘分析工具。
select data.*, location.remote
from (
select e.last_name, e.department_id, d.department_name
from employees e
left outer join department d
on (e.department_id = d.department_id)
) data inner join
(
select s.remote,s.department_id
from source s
inner join location l
on s.location_id = l.id
) location on data.department_id = location.department_id;
我们的目标是需要知道顶层的 select list 中包含哪些字段(column),并且这些字段的源数据来自其它哪些表和字段。一个理想的结果应该如下图所示:
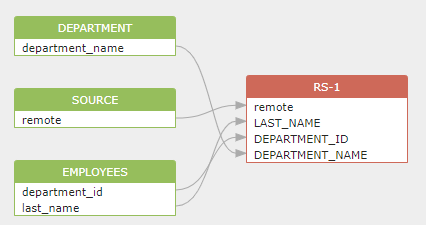
为了得到上面的结果,我们需要做这些事情:
1、自动展开 data.* 中的 * (asterisk),找到对应的字段。
2、为 select list 中的每个字段进行数据溯源,找到原始的表和字段,这个过程可能需要进行多层次的溯源,直到找到最终的数据源。
关于 * 号的自动展开
Select list 中的 * (asterisk) 代表该 relation 中的所有字段,需要展开为具体的字段名,在本例中,Gudu SQLFlow 可以根据 SQL 中提供的上下文信息,进行自动展开。但有时候,SQL 语句本身无法提供足够的信息以确定 * 到底包含了哪些字段,这时,你需要提供元数据 (metadata) 信息给 Gudu SQLFlow, 以便正确展开星号。
Gudu SQLFlow 提供了三种途径来帮你快速获得复杂 SQL 语句的血缘关系,方便你在不同场合使用。
1. Gudu SQLFlow UI
你可以直接访问 Gudu SQLFlow Cloud 版本,无需安装任何软件,即可使用。使用方法很简单,直接把需要处理的 SQL 语句 paste 到输入区域,然后点击 Visualize 即可。
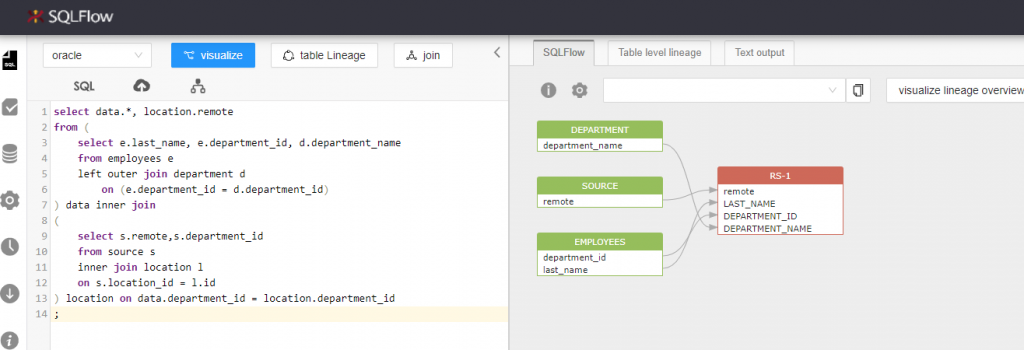
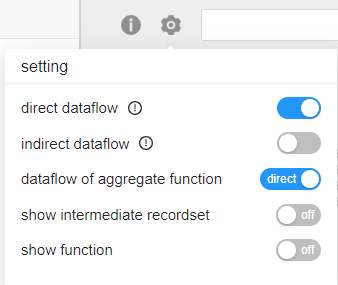
我们可以忽略数据血缘的中间处理步骤及详细的信息,直接展示源数据(source data)和目标数据(target data),获得如上图的简洁结果,采用的 setting 设置如下:
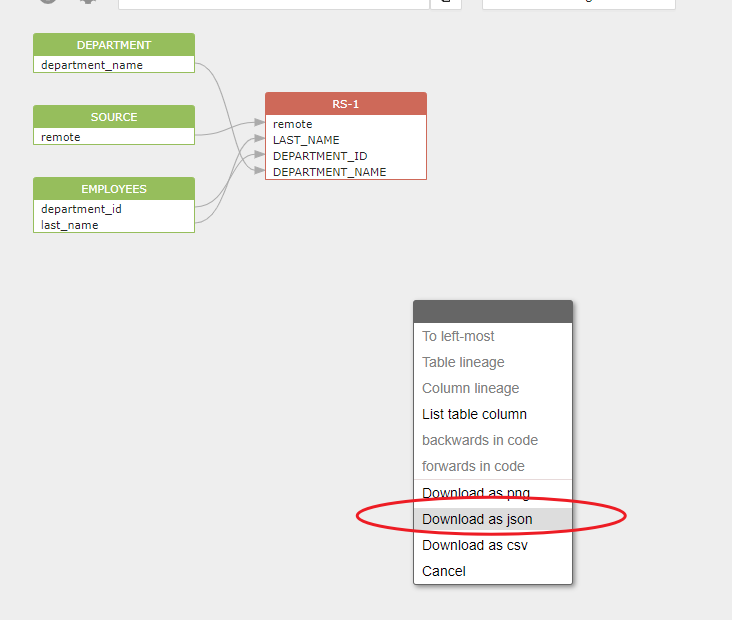
你可以下载包含了数据血缘关系的 JSON 结果,进行进一步的处理。( 数据血缘的存放路径: data -> sqlflow -> relationships)
2. Gudu SQLFlow Rest API
你可以在代码中调用 Gudu SQLFlow Rest API 来自动递交需要处理的 SQL 语句,并实时获得处理结果,然后在你的代码中对返回的数据血缘关系按业务需求进行处理。
为了使用 Gudu SQLFlow Rest API, 你需要一个 Gudu SQLFlow Cloud Premium Account, 这里有详细的教程。或者在你的公司内部安装 Gudu SQLFlow On-Premise Version 来使用 Rest API。
- Python code 连接部署在企业内部的 Gudu SQLFlow 服务器 ( Gudu SQLFlow on-premise server ) 来获取数据血缘结果。
- Python code 连接 SQLFlow cloud server 来获取数据血缘结果。
点击这里,可以查看利用以上 Python 代码分析产生的数据血缘结果。( 数据血缘的存放路径: data -> sqlflow -> relationships)
3. Gudu SQLFlow Java library
你也可以使用 Gudu SQLFlow Java 类库来分析 SQL 语句的数据血缘。利用 Gudu SQLFlow Java 类库的好处是你无需安装 Gudu SQLFlow 服务器软件,并且可以独立运行,不依赖任何第三方 Java 类库,方便集成到你自己的项目中。
我们为你创建了一个 Java demo 程序,你可以拿来直接编译运行。为了获取本文中 SQL 语句顶层 select list 返回的所有字段及他们的数据源,我们可以用以下参数运行该 Java demo:
/s /topselectlist生成的数据血缘关系以 XML 格式存储,可以点击这里打开这个 XML 文件。