数据仓库和数据湖中处理数据用的最多的工具就是 SQL 语言,无论是数据加载、数据转换、还是数据清洗,都会用到 SQL 查询语言,更不用说数据查询和分析了。
在数据仓库和数据湖中,数据血缘对提升企业数据质量有着非常重要的作用,关于数据血缘在企业数据治理中的重要作用,可以参考这篇文章,在本文中,我们主要介绍如何发现 SQL 语句中的数据血缘,哪些 SQL 语句中隐藏着数据血缘关系。如果你想知道自己公司的数据仓库和数据湖中有哪些数据血缘,本文教你在5分钟内,通过分析你企业中已经存在的那些 SQL 语句,来快速获得数据血缘信息,从而可以进行数据溯源分析、分析某个表的字段如果修改,会对哪些系统产生影响。
文章中的分析方法适用于各种数据库的 SQL 语句,例如主流的关系型数据库 DB2, MySQL, Oracle, PostgreSQL, SQL Server, 又如数仓系统例如 Greenplum, HP Hana, Teradata, Vertica 等,也适用基于云技术的数据湖例如 Azure Synapse Analytics, AWS Redshift, Google BigQuery,Snowflake。
1、什么是数据血缘
首先我们需要知道什么是数据血缘,维基百科的定义在这里。关于数据血缘的入门知识,可以看这里。我们这里仅讨论数据库中各个表或视图(view)间的数据血缘,即各个表和视图间的数据是如何关联和流动的。
我们以一个网上商店的数仓作为例子,来讲解数据血缘是如何产生的。该数据库包含8张表,展示了原始数据的导入,清洗和转换过程。
1.1 外部数据导入表
数据从外部系统进入本系统,落地到以下3张表:
raw_customers
raw_orders
raw_payments1.2 中间表
从上面的落地表到这里的中间表,可以进行数据清洗等工作:
stg_customers
stg_orders
stg_payments1.3 数仓模型表
中间表的数据经过逻辑转换,按照业务需要的格式,存放到下面的模型表中,供业务人员查询分析:
customers
orders2、数据血缘的产生
用不同的 SQL 语句,可以在数仓的不同表间进行数据加载、清洗、转换等工作,随着数据在不同表和视图间的移动、转换,数据血缘关系因此产生。
2.1 Insert 语句
Insert 语句用来往一个表中插入数据。但是普通的 Insert 语句无法产生数据血缘:
INSERT INTO raw_customers (id, first_name, last_name) VALUES(0, '', '');因为数据源都是常数,不是来自另一个表。而下面这个 Insert SQL 语句将产生数据血缘/关联:
INSERT INTO stg_customers (customer_id, first_name, last_name)
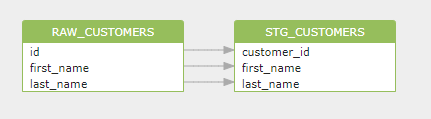
SELECT id, first_name, last_name FROM raw_customers;下图表示产生的表级的数据血缘关系,表示 stg_customers 表的数据来自 raw_customers 表。熟悉 SQL 语言的一眼就能看出来。

下图表示产生的字段级的数据血缘关系,表示 stg_customers 表中 customer_id 字段的数据来自 raw_customers 表中 id 字段。
2.2 Create view 语句
Create view 语句表示创建一个视图,该视图中的数据来源于创建视图时指定的基础表。很明显,基础表和该视图之间存在数据血缘关系。
CREATE OR REPLACE VIEW stg_customers(customer_id,first_name,last_name)
AS
SELECT
id,
first_name,
last_name
FROM raw_customers 产生的字段级的数据血缘如下,我们可以从 create view SQL 语句中发现 raw_customers 表和 stg_customers 视图间的数据关联。
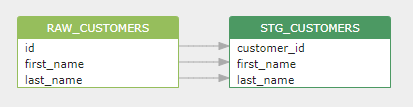
同样的,在数仓中普遍使用的 CTAS 语句 (Create Table As Select) 也会在源数据表和目标表间建立数据血缘关系。
2.3 Merge 语句
Merge 语句根据源数据表中的数据,在目标表中插入、更新或删除数据。由此,在源数据表和目标表间会建立数据血缘关系。
MERGE stg_orders AS Target
USING raw_orders AS Source
ON Source.id = Target.id
-- For Inserts
WHEN NOT MATCHED BY Target THEN
INSERT (id,user_id,order_date,status)
VALUES (id,user_id,order_date,status)
-- For Updates
WHEN MATCHED THEN UPDATE SET
Target.user_id = Source.user_id,
Target.order_date = Source.order_date,
Target.status = Source.status
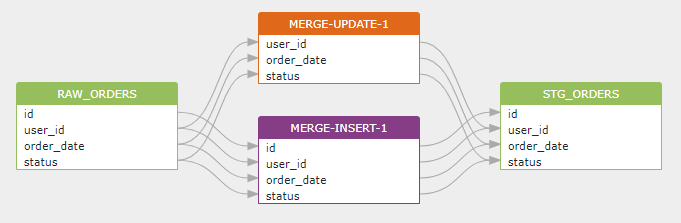
上面这个 Merge 语句表示:如果在 stg_orders 表中找到和 raw_orders 表中具有相同 id 的数据记录,则用 raw_orders 表中的数据更新 stg_orders 表中对应的数据,如果没找到,则在 stg_orders 表中新插入一条来自 raw_orders 表的数据记录。产生的数据血缘如下图:
2.4 其它 SQL 语句
以上介绍了 SQL 语言中最常用的一些会产生数据血缘的 SQL 语句,他们让数据在不同的表或视图间发生了流动,从而产生了数据血缘,这些 SQL 一般都是 DML ( Data Manipulation Language ), DDL ( Data Definition Language )。其它的 SQL 语句还有 Update, Create external table, 存储过程等。
3、为什么需要一个自动发现数据血缘的工具
通过以上学习,你已经可以通过阅读 SQL 语句来发现其中的数据血缘,并依靠发现的数据血缘来对数仓系统做影响分析等工作。但在实际业务系统中,通过人工阅读 SQL 语句来发现数据血缘并不现实,你会碰到以下典型问题。
3.1 SQL语句的复杂性
实际业务系统中应用的 SQL 语句会非常复杂和冗长,包含多层的子查询嵌套、用 CASE 表达式进行数据的筛选、使用存储过程进行复杂的逻辑运算,一般会用到游标 ( cursor) 和动态语句。仅以 2.2 中使用的 create view 语句为例,实际业务系统中为了进行字段名的转换,可能使用下面的这个 SQL 语句,你还能轻松的梳理出数据血缘关系吗?
CREATE OR REPLACE VIEW stg_customers
AS WITH source AS (
SELECT raw_customers.id,
raw_customers.first_name,
raw_customers.last_name
FROM raw_customers
), renamed AS (
SELECT source.id AS customer_id,
source.first_name,
source.last_name
FROM source
)
SELECT renamed.customer_id,
renamed.first_name,
renamed.last_name
FROM renamed;试试用一个数据血缘分析工具来分析一下上面这个 SQL 语句的数据血缘,不到一秒的时间,你就可以获得结果。
3.2 需要处理庞大的 SQL 语句
在实际的数仓环境中,一般有上百个表和视图,包含成千上万个字段,用来进行数据加载、清洗、 转换、分析的 SQL 代码可能有几千行或者更多,并且这些 SQL 代码随着业务应用的发展不停的更新变化,这时需要一个能够自动扫描、分析 SQL 语句的工具,来处理企业环境中这些复杂而庞大的 SQL 代码,精准的发现其中的数据血缘。
3.3 需要快速的发现数据血缘
为了提高竞争力,现代企业普遍采用商业智能、机器学习等系统来充分挖掘、利用企业数据的价值。为了快速相应业务部门的分析需求,数仓或数据湖中的数据和结构必须能够进行快速的调整和重构,增加新的数据源、移除不用的老数据,在数仓数据的快速调整迭代过程中,需要有可靠的元数据管理工具、数据血缘分析工具来为数据质量和数据安全保驾护航,分析数仓中数量众多的 SQL 代码,快速获得血缘关系,无疑具有重要的价值。
3.4 任然可以在5分钟内搞定 SQL 代码中的数据血缘关系
虽然面临以上挑战,如果拥有一款可以自动扫描、分析 SQL 代码,并且迅速准确的输出数据血缘的工具,那么我们仍然可以在5分钟内搞定企业数仓中的 SQL 代码所包含的数据血缘关系。
Gudu SQLFlow 是一款能够分析多达 20 几种主流数据库 SQL 语言的数据血缘分析工具,支持复杂的 SQL 嵌套、存储过程、动态SQL语句。Gudu SQLFlow Cloud 版本支持开箱即用,无需安装任何软件。Gudu SQLFlow 私有化部署版本( on-premise version )可以部署在你的企业内部,直接连接数据库,自动从数据库中分析获取数据血缘关系,而不用担心数据的安全问题。