l 数据血缘关系(data lineage)
数据血缘属于数据治理中的一个概念,是在数据溯源的过程中找到相关数据之间的联系,它是一个逻辑概念。数据治理中经常提到血缘分析,血缘分析是保证数据融合的一个手段,通过血缘分析实现数据融合处理的可追溯。数据血缘是指数据产生的链路,直白点说,就是我们这个数据是怎么来的,经过了哪些过程和阶段。
l SQLFlow是什么?
SQLFlow 通过分析各种数据库对象定义(DDL)语句、数据操作(DML) 语句、ETL/ELT中使用的存储过程(Proceudre,Function)、 触发器(Trigger)和其他 SQL 脚本,给出完整的数据血缘关系。它不仅可以展现对象间的关系,也可以帮你提取表的字段。
官方链接:https://sqlflow.gudusoft.com
Grabit 可以帮助你轻松使用sqlflow,并带来愉悦的使用感受。Grabit 是 SQLFlow 的一个配套工具,它从各种数据源中为 SQLFlow 收集 SQL 脚本,然后上传到 SQLFlow 中,对这些 SQL 脚本进行数据沿袭分析。分析结果可以在浏览器中查看。同时,数据沿袭结果将被提取到安装 Grabit 的目录中,如果需要,可以将 JSON 结果上传到 Neo4j 数据库。

使用命令方式启动Grabit:
- mac & linux
./start.sh -f <path_to_config_file>
note:
path_to_config_file: the full path to the config file
eg:
./start.sh -f config.txt
- windows
start.bat -f <path_to_config_file>
note:
path_to_config_file: the full path to the config file
eg:
start.bat -f config.txt上述脚本中会均需要使用到配置文件(config.txt),下面详细介绍一下配置文件的基本格式:
配置文件基本格式:
{
"databaseServer":{
"hostname":"ipaddr",
"port":"1521",
"username":"username",
"password":"SQeEs44QL8NbLCpqYig4DA==gbtepted",
"database":"orcl",
"extractedDbsSchemas":"SQLFLOWDB1,SQLFLOWDB2,SQLFLOWDB3",
"excludedDbsSchemas":"",
"extractedStoredProcedures":"",
"extractedViews":"",
"enableQueryHistory":false,
"queryHistoryBlockOfTimeInMinutes":30,
"snowflakeDefaultRole":null,
"queryHistorySqlType":null
},
"gitServer":null,
"SQLInSingleFile":null,
"SQLInDirectory":null,
"SQLFlowServer":{
"server":"http://xxxx.sqlflow.cn",
"serverPort":"8081",
"userId":"userid",
"userSecret":null
},
"atlasServer":null,
"neo4jConnection":null,
"SQLScriptSource":"database",
"lineageReturnFormat":null,
"databaseType":"oracle",
"isUploadNeo4j":0,
"enableGetMetadataInJSONFromDatabase":0,
"isUploadAtlas":0,
"lineageReturnOutputFile":null
}其中databaseServer和SQLFlowServer是您需要重点进行配置的,上图中加粗斜体均需按照实际情况进行配置:
databaseServer配置:
hostname
Grabit 连接的数据库服务器的 IP。
port
Grabit 连接的数据库服务器的端口号。
username
用于登录数据库的数据库用户。
password
数据库用户的密码。
注意:密码可以使用工具[#Encrypted](#Encrypted password)进行加密,使用加密密码更安全。
database
Oracle实例名称。
SQLFlowServer配置:
本地版本sqlflow的示例配置:
“SQLFlowServer”:{
“server”:“ 127.0.0.1 ”,
“serverPort”:“ 8081 ”,
“userId”:“ gudu|0123456789 ”,
“userSecret”:“ ”
}
云版本的示例配置:
"SQLFlowServer" :{
"server" : " https://api.gudusoft.com " ,
"serverPort" : " " ,
"userId" : "这里是你自己的用户 id " ,
"userSecret" : "这里是你自己的密钥"
}
相对于其他数据库,Oracle数据库中有一种特殊的对象类型是package,它是一组程序的集合,sqlflow能够支持该类对象中包含的血缘关系解析。下面详细介绍sqlflow对package对象的支持
示例代码1,SQLFLOWDB1下的表DBINFODETAIL的定义
-- SQLFLOWDB1.DBINFODETAIL definition
CREATE TABLE "SQLFLOWDB1"."DBINFODETAIL"
( "DBID" NUMBER,
"NAME" VARCHAR2(9),
"INSTANCE_NAME" VARCHAR2(16),
"VERSION" VARCHAR2(17),
"RAC" VARCHAR2(3),
"HOST_NAME" VARCHAR2(64)
) SEGMENT CREATION IMMEDIATE
PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255
NOCOMPRESS LOGGING
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1
BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "USERS" ;示例代码2,SQLFLOWDB2下的chen_pack包
CREATE OR REPLACE package SQLFLOWDB2.chen_pack
is
function f_c_getstaffNum(in_status in varchar2) return number;
procedure p_c_sendmsg(receiver in varchar2,content in varchar2);
end;
CREATE OR REPLACE package body SQLFLOWDB2.chen_pack
as
function f_c_getstaffNum(in_status in varchar2)
return number
as
outnum number;
begin
select count(1) into outnum from t_ucp_staffbasicinfo g where g.staffidstatus = in_status;
return outnum;
end f_c_getstaffNum;
procedure p_c_sendmsg(receiver in varchar2,content in varchar2)
as
begin
insert into t_c_msg(sender,receiver,content,sendtime)
SELECT DBID, NAME, INSTANCE_NAME, SYSDATE FROM SQLFLOWDB1.DBINFODETAIL;
-- values('10658666',receiver,content,sysdate);
commit;
end p_c_sendmsg;
end chen_pack;示例代码3:SQLFLOWDB3下的sqlflow包
CREATE OR REPLACE package SQLFLOWDB3.sqlflow
is
procedure p_getdata;
end;
CREATE OR REPLACE package body SQLFLOWDB3.sqlflow
as
procedure p_getdata
as
begin
insert into get_c_msg(sender,receiver,content,sendtime)
SELECT * FROM SQLFLOWDB2.t_c_msg where sender='1553407471';
commit;
end p_getdata;
end sqlflow;上述来源不同schema下的三个对象间应具有以下血缘关系:
SQLFLOWDB1.DBINFODETAIL(DBID, NAME, INSTANCE_NAME, SYSDATE)->
SQLFLOWDB2.t_c_msg(sender,receiver,content,sendtime) -> SQLFLOWDB3.get_c_msg(sender,receiver,content,sendtime)通过使用grabit上传该实例下的对象到sqlflow分析,可以看到目标表及两个package包均被成功解析,如下:
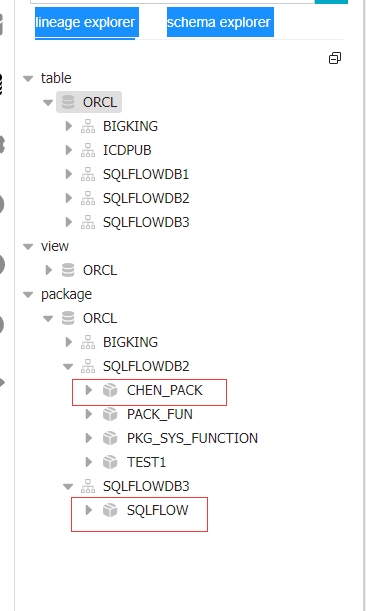
此时,查看对象间数据血缘分析如下:

关于package及grabit的进一步了解及使用,请访问sqlflow官方网站。
sqlflow数据血缘分析器: https://sqlflow.gudusoft.com
马哈鱼数据血缘分析器中文网站: https://www.sqlflow.cn