随着数字化转型深度推进,企业产生的数据量呈现出爆发式增长,数据之间的关系也变得越发复杂,导致数据溯源以及数据模型修改后业务分析困难。本文中的用户是一家以金融投资管理软件服务为核心,专注于金融资管业务和数据治理的金融科技公司。用户通过集成SQLFlow数据血缘分析,助力企业完善数据治理能力,发挥出数据价值。
本文重点介绍用户集成SQLFlow数据血缘分析的方法及其产生的产品价值。
用户需要将数据血缘分析能力集成在其“数据资产管理系统”内,并分发给其用户使用。所以用户采用了GSP(数据血缘分析SDK)+ ingester(数据摄取)+ widget(数据血缘展示)组合的方式完成了系统集成。集成方法如下图所示:
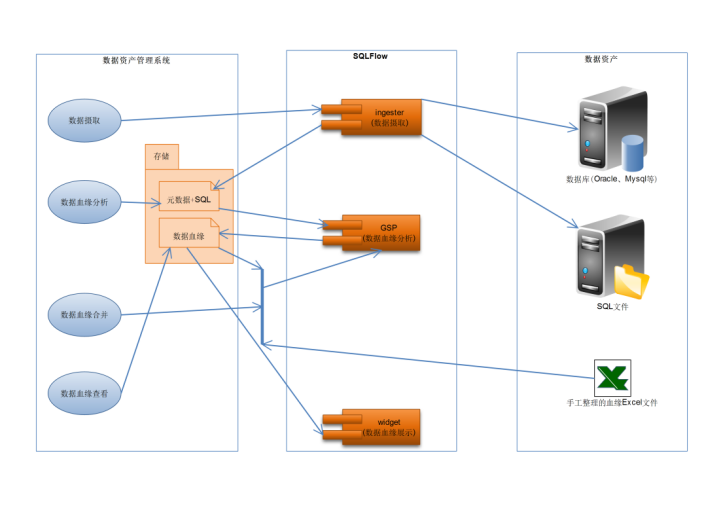
用户“数据资产管理系统”通过集成SQLFlow产品,实现了数据摄取、数据血缘分析、数据血缘合并和数据血缘可视化功能。
1、数据摄取
数据摄取是将要分析血缘的SQL从数据库及sql脚本文件中提取出来,为数据血缘分析做数据准备。
利用sqlflow-ingester的SDK可完成数据摄取,本案例用到了sqlflow-exporter、sqlflow-extractor2个SDK。
sqlflow-exporter:可连接数据库,提取数据库的元数据、DDL(View、存储过程、自定义函数、触发器、Package等)以及HistoryLog。
sqlflow-extractor:负责处理输入的原始数据文件,例如 log 文件,各种脚本文件(从中抽取需要被处理的SQL语句及元数据),包含SQL语句的CSV文件等,把这类文件统一转换为 SQLFlow 可以处理的 SQL 文件。
用户集成sqlflow-ingester实现了数据资产管理中的元数据发现功能,支持对SQL语句、存储过程、ETL脚本等文件进行自动化采集分析。目前具备了oracle、hive、mysql、greenplum、impala、PostgreSQL等数据库的采集能力。
2、数据血缘分析
数据血缘分析是通过Java核心库GSP实现的。GSP通过分析数据摄取阶段得到的元数据和SQL得到数据血缘分析结果。支持json、xml和csv三种输出格式。
用户要分析的数据量比较大,血缘分析需要耗费较高的内存资源。用户单独开发了一个Spring Boot微服务组件来做数据血缘分析,采用了异步排队的策略,保证了系统的健壮性。
3、数据血缘合并
除了SQL分析得出的血缘外,用户还有一些手工整理的血缘数据,希望将这些血缘跟分析出来的数据血缘进行合并,能看到更完整的数据血缘流图。
GSP支持数据血缘合并,可以将sql解析得到的数据血缘对象和csv格式的数据血缘合并成一个数据血缘对象。
4、数据血缘可视化
将数据血缘分析结果可视化展示,可以更直观方便地帮助用户查看分析血缘。SQLFlow将前端数据血缘展示功能封装成了独立的JS组件库widget,可以很方便地集成到web端程序中,极大降低了开发难度。widget数据血缘可视化界面如下图所示:
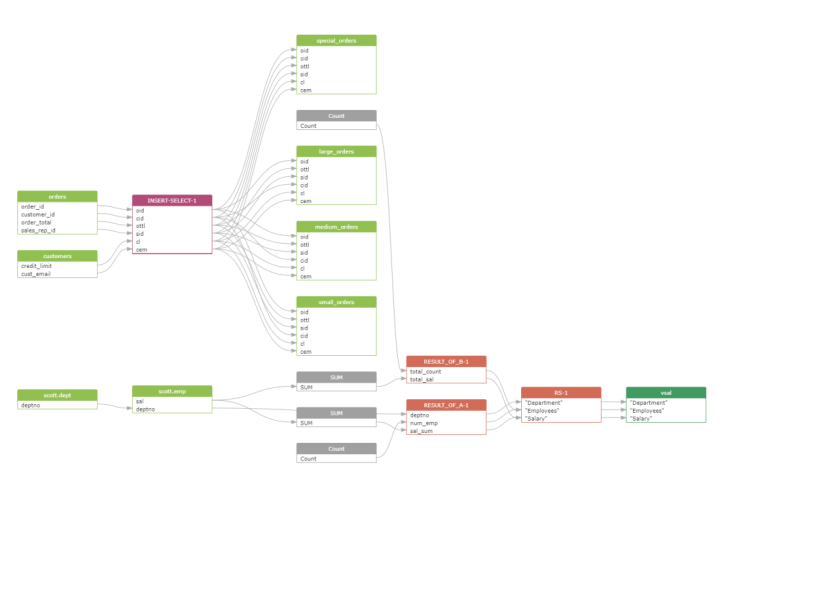
为了更好的演示GSP + ingester + widget集成方式,我们做了以下2个Demo供参考:
Java集成: https://github.com/sqlparser/java_data_lineage
Python集成: https://github.com/sqlparser/python_data_lineage
用户数据血缘分析能力可覆盖数据系统建设中各类血缘采集场景需求,对数据加工脚本精准解析,形成数据血缘关系图,回答出“数据从哪里来,到哪里去”的问题,对数据治理、数据挖掘、数据质量、数据分析等方面都有极为重要的作用。据用户反馈,集成数据血缘分析能力后,其产品在以下几个方面创造了很大的价值:
1、助力数据清理
在血缘关系图中发现数据上下游都不存在时,识别为孤岛数据,及时清理。防止数据错误使用和不必要的存储和计算。
2、助力数据决策
当系统进行升级改造的时候,如果修改了数据结构ETL 程序等元数据信息,依赖数据的影响性分析,可以快速定位出元数据修改会影响到哪些下游系统,从而减少系统升级改造带来的风险。
3、助力数据治理
在数据质量中检查出问题的时候,通过数据血缘关系图,可以清晰的看到数据产生、流转、使用的整个前后过程,方便的了解到数据的处理过程是否符合数据质量处理要求。
4、助力数据保护
当识别敏感数据和风险点时,通过数据血缘关系图,可以追溯数据来源,将涉及到字段列采取相应的脱敏和权限措施,数据防止泄露。