本文中描述的数据集市搭建方案是一家跨国公司在AWS平台上的具体实践案例。我公司参与其中的数据血缘部分的建设,SQLFlow数据血缘分析工具在该方案中帮助用户实现了数据血缘分析。
用户使用Redshift 数据库仓库进行数据集市开发。从各种数据源提取数据,并将数据存储到AWS S3中,通过将S3中的数据映射到Redshift Spectrum,实现对大规模数据的高效查询,然后根据设计好的数据集市数据模型,将S3中的数据进行各种数据转换和审查,最终将处理结果数据存储到Redshift数据集市库中,经过测试后数据集市上线运维。从数据准备到数据集市上线的整个开发流程如下图所示:

数据集市开发过程中涉及到多个环节,其中一些环节会产生数据血缘关系。数据血缘关系是指数据从源头到目的地的整个流转过程,包括数据的来源、经过的转换、以及最终存储的位置。在 AWS 平台上,特别是使用 Redshift 数据库进行数据集市开发时,理解和管理数据血缘关系对于确保数据质量、进行数据治理以及优化数据处理流程至关重要。
产生数据血缘关系的环节:
1、数据提取:从各种数据源提取数据到 S3 时,会产生数据的初步血缘关系,记录了数据从源系统到 S3 的移动。
2、S3 到 Redshift Spectrum 的映射:将 S3 中的数据映射为 Redshift Spectrum 的外部表时,进一步定义了数据从 S3 到 Redshift 的流转路径。
3、数据转换:在数据转换过程中,原始数据会经过一系列的转换操作,生成新的数据集。这一过程中产生的血缘关系记录了数据如何被转换以及转换的逻辑。
4、数据加载:将转换后的数据加载到 Redshift 的持久化表中,这一步骤也会产生数据血缘关系,记录了数据从临时表到持久化表的移动。
数据血缘分析方案设计:
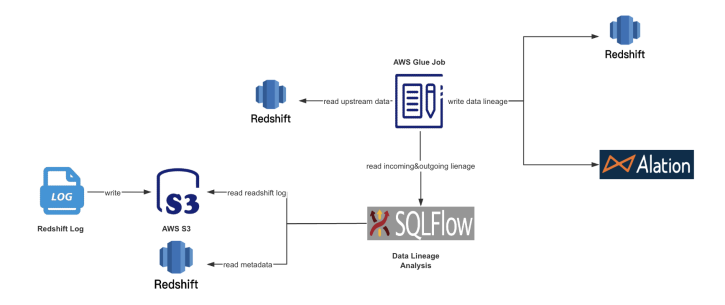
1、采用SQLFlow的私有化部署版本作为数据血缘分析工具,通过REST API做系统集成。
2、定义血缘关系模型:首先需要定义一个数据血缘关系模型,明确记录数据源、转换步骤、目标表以及每个步骤的依赖关系。 模型定义时可以参考SQLFlow的dataflow对象,该对象定义了元数据和数据血缘关系包含的所有信息。
3、血缘数据的收集:在数据处理的每个环节,通过日志、元数据管理工具或编程方式收集数据血缘信息。由于用户整个数据集市的开发都是围绕Redshift数仓展开的,所以分析Redshift日志中的sql可以覆盖所有数据血缘产生环节。另外为了保证血缘分析的准确性,还需要提取Redshift的metadata辅助分析。
4、血缘关系的存储与管理:设计一个中心化的血缘关系数据库或使用现有的数据目录服务来存储和管理血缘信息。用户将数据血缘存储到了Redshift库中,并上传到数据资产管理系统Alation进行管理。
数据血缘分析实施步骤:
1、集成血缘收集
a)安装SQLFlow私有化部署regular版本。
b)使用sqlflow-ingester的submitter工具,每天定时自动执行一次增量的SQLFlow数据血缘分析。submitter会拉取最近30天的Redshift日志,并将日志文件中的sql提取出来存为后缀为sql的文本文件,同时submitter还会连接Redshift数据库将完整的元数据提取出来存为metadata.json, 最后submitter将提取到的sql文件和metadata.json压缩成一个zip包,递交给SQLFlow做数据血缘分析。整个过程由submitter自动完成,无需人工干预。
2、血缘数据存储
编写Python脚本,每天凌晨定时执行,在脚本内调用SQLFlow的REST API查询数据血缘分析结果,并将血缘数据转成用户的数据血缘关系格式,存入Redshift数据库。同时上传到Alation数据资产管理平台。
3、实现血缘查询与分析功能
通过集成SQLFLow的widget前端组件可以实现数据血缘可视化。用户的数据资产管理是通过Alation实现,数据分析是通过商业智能BI软件Qlik Sense实现。在这两个系统中,点击要查询的表、视图或者字段可以链接到一个widget生成页面查看数据血缘。
用户用到的数据血缘分析功能主要有:
a)to left most 当前表/视图/字段的数据最初来自哪些表/视图/字段。
b)up stream 当前表/视图/字段的数据来自哪些表/视图/字段。
c)down stream 当这个表/视图/字段的数据发生变动时,会影响哪些表/视图/字段。
d)outgoing 用户在做报表查询时,会用到一些表或视图。需要通过分析SQL语句,列出这些给报表提供数据的表,并回溯到给这些表提供数据的数据集市表,通过数据集市表,可以继续回溯到更早的源系统。
4.血缘信息的维护与更新
确保数据处理流程中的变更能够及时反映到血缘信息中,定期审核和更新血缘数据库,保持数据血缘信息的准确性和时效性。 编写Python脚本,每日凌晨定时执行,脚本中会对数据的合法性进行校验,校验结果会自动发邮件到用户运维人员电子邮箱。
实施后的系统拓扑图如下所示:
通过上述设计方案和实施步骤,可以有效地管理和分析数据集市开发过程中产生的数据血缘关系,从而提高数据质量,优化数据处理流程,并支持数据治理和合规性要求。