一、Job基本知识
前面文章中已介绍马哈鱼的基本功能,其中一个是job,job其实是一个任务集合处理的概念,就是让用户通过job,可以一次递交所有需要处理的 SQL,SQLFlow处理这些 SQL,把所有的数据血缘都分析出来。从用户角度,job包含job list和The Latest Job。其中,job list是当前用户所有的job。而The Latest Job是所有用户job中最新的job列表。本文向您重点介绍job的作用及用法。
job是马哈鱼收集各种数据源的数据后分析的任务,现在马哈鱼平台上支持三种方式: 1、上传文件(支持SQL脚本文件,Spark的python脚本文件和CSV文件,支持的CSV文件的文档;
2、从数据库中收集metadata,其实就是收集表,存储过程,视图的DDL,metadata结构文档:
3、上传文件并从数据库中收集metadata,同时也从数据库中收集metadata的目的是为了解决文件中SQL脚本分析过程中产生的Orphan Column的异常(详情参阅《利用元数据提高 SQLFlow 血缘分析结果准确率》)。
二、如何使用Job进行血缘分析
job是一个与用户紧密关联的功能,如果您以访客身份登录马哈鱼官网https://sqlflow.gudusoft.com/后,在没有登录时,您无法正常使用job功能,其中job list列表为空,The Latest Job需要登录后才能进行查看。如下图:

对任何用户,马哈鱼官方提供一个示例job作业,帮助用户快速熟悉job的使用。
1、Job支持的文件格式
- 单个 SQL 文件。
- 多个 SQL 文件,可以包含子目录,打包成zip文件再上传。
- 从 git server 上获取的所有 SQL 文件
- 从数据库中获取的,包含元数据和DDL语句的,专门格式的 JSON文件。
- 包含 SQL 语句的 CSV 文件
- 其它 grabit 工具可以事先处理文件,抽取出 SQL 提交给 SQLFlow 来分析血缘。
2、创建一个新的job
客户在创建job前,必须先进行sql source选择,不同的sql source对应填充项是不同的。马哈鱼job目前支持三种sql source,分别是:
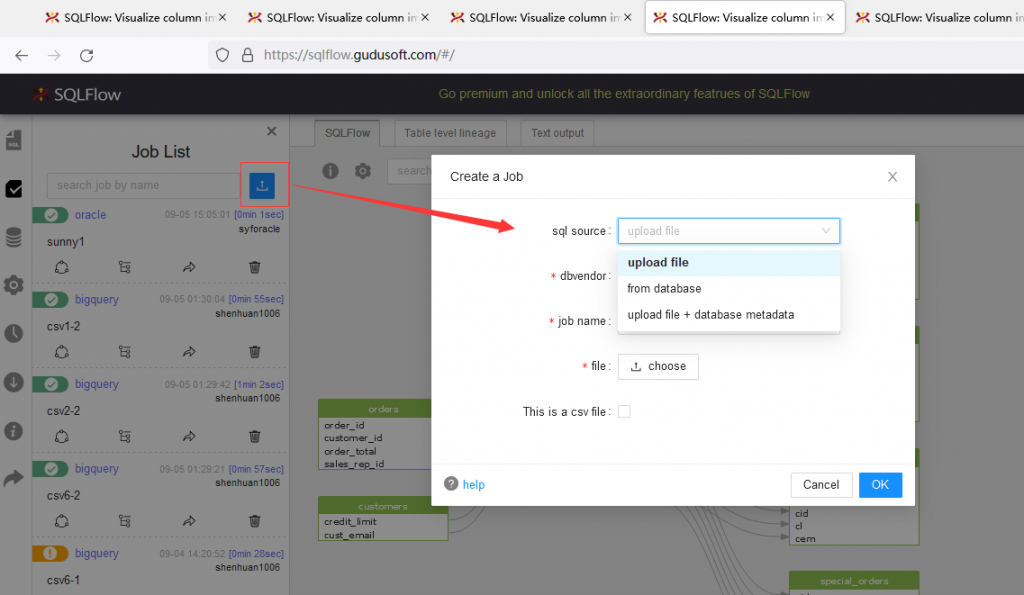
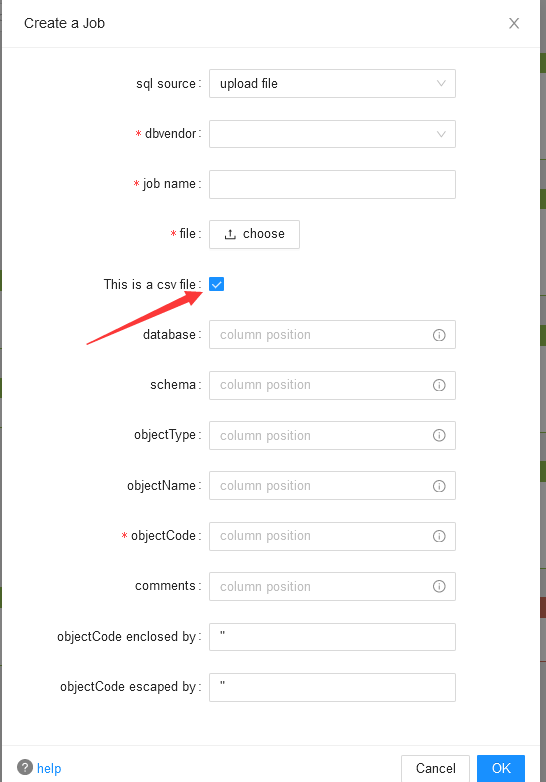
- upload file仅上传SQL文件,马哈鱼会根据上传的SQL语句进行解析所有溯源关系,它必须填写dbvendor、jobname、file等基本信息,如果是csv文件,还需要填写database、schema、objectType、objectCode等在csv中的对应列名称。如下图:
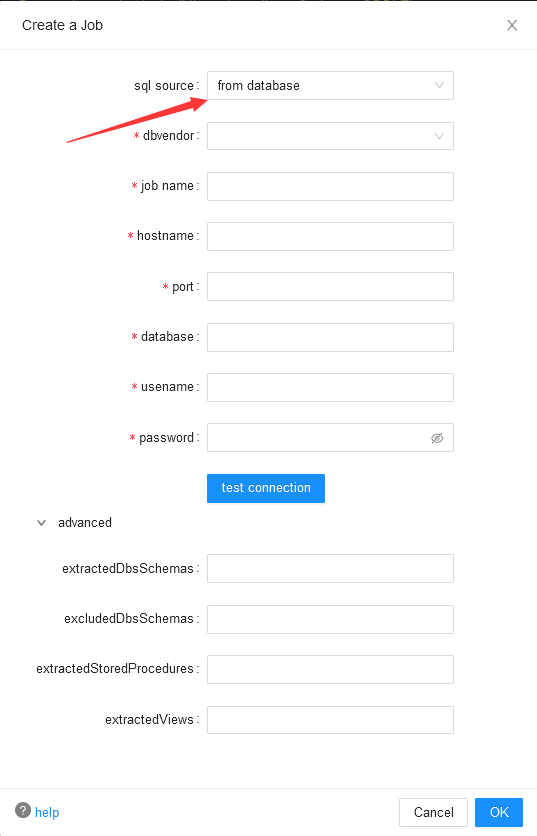
- from database客户需要填写用户数据库连接信息,通过直连客户数据库,马哈鱼将从数据库中直接获取对象定义及它们间的逻辑关系,该类型job将会根据客户选择的数据库所有或特定schema下所有的对象血缘关系进行分析。通过下图中advanced选项,客户可以限制马哈鱼job的分析范围,如果不选择默认分析当前连接数据库中所有的对象间的血缘关系。
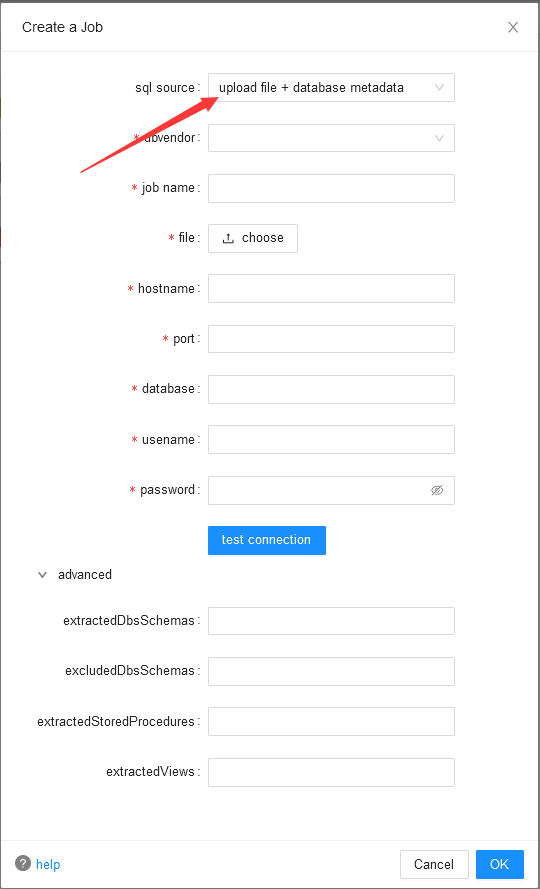
- upload file+database metadata该方式是将上述两种方式进行整合,更加灵活,客户可以通过连接到数据库方式对任何自定义语句集合进行集中分析,该方式灵活且能避免较多因sql语句书写不规范带来的问题。
3、使用已有的job
你设计一下,看看如何为所有的用户,包含standard 用户预设一个sample job 目的是为了可以让用户首次登录后马上可以体验job的功能,可以查看该sample job的data lineage
job

点击upload按钮,可以上传文件,创建一个job。当job处理完成后,可以点击view lineage,打开处理结果。
当客户登录到马哈鱼后,在左侧功能导航栏中有两个job入口,分别是job list和The Latest Job,其中,job list显示该用户下所有的job,而The Latest Job会使用新窗口自动加载最新的一个job的分析结果。

三、参考
马哈鱼数据血缘分析器: https://sqlflow.gudusoft.com
马哈鱼数据血缘分析器中文网站: https://www.sqlflow.cn